Wolfram Data Repository
Immediate Computable Access to Curated Contributed Data
A dataset for question answering and text understanding in both Hindi and English
The bAbI-QA is a dataset for question answering and text understanding. The dataset is composed of a set of contexts, with multiple question-answer pairs available based on the contexts. Furthermore, the dataset is in both English and Hindi and is divided into 20 tasks:
Task 1: Single Supporting Fact
Task 2: Two Supporting Facts
Task 3: Three Supporting Facts
Task 4: Two Argument Relations
Task 5: Three Argument Relations
Task 6: Yes/No Questions
Task 7: Counting
Task 8: Lists/Sets
Task 9: Simple Negation
Task 10: Indefinite Knowledge
Task 11: Basic Coreference
Task 12: Conjunction
Task 13: Compound Coreference
Task 14: Time Reasoning
Task 15: Basic Deduction
Task 16: Basic Induction
Task 17: Positional Reasoning
Task 18: Size Reasoning
Task 19: Path Finding
Task 20: Agent’s Motivations
The "ContentElements" field contains three options, "TrainingData", "TestData" and "Dataset". The first two provide access to data formatted for common training tasks. They are extracted from the 10,000k version in English.
The full dataset "Dataset" contains more information, including the Hindi version of the dataset.
(6 columns, 161516 rows)
Retrieve the ResourceObject:
| In[1]:= |
| Out[1]= |  |
View the data:
| In[2]:= |
| Out[2]= | 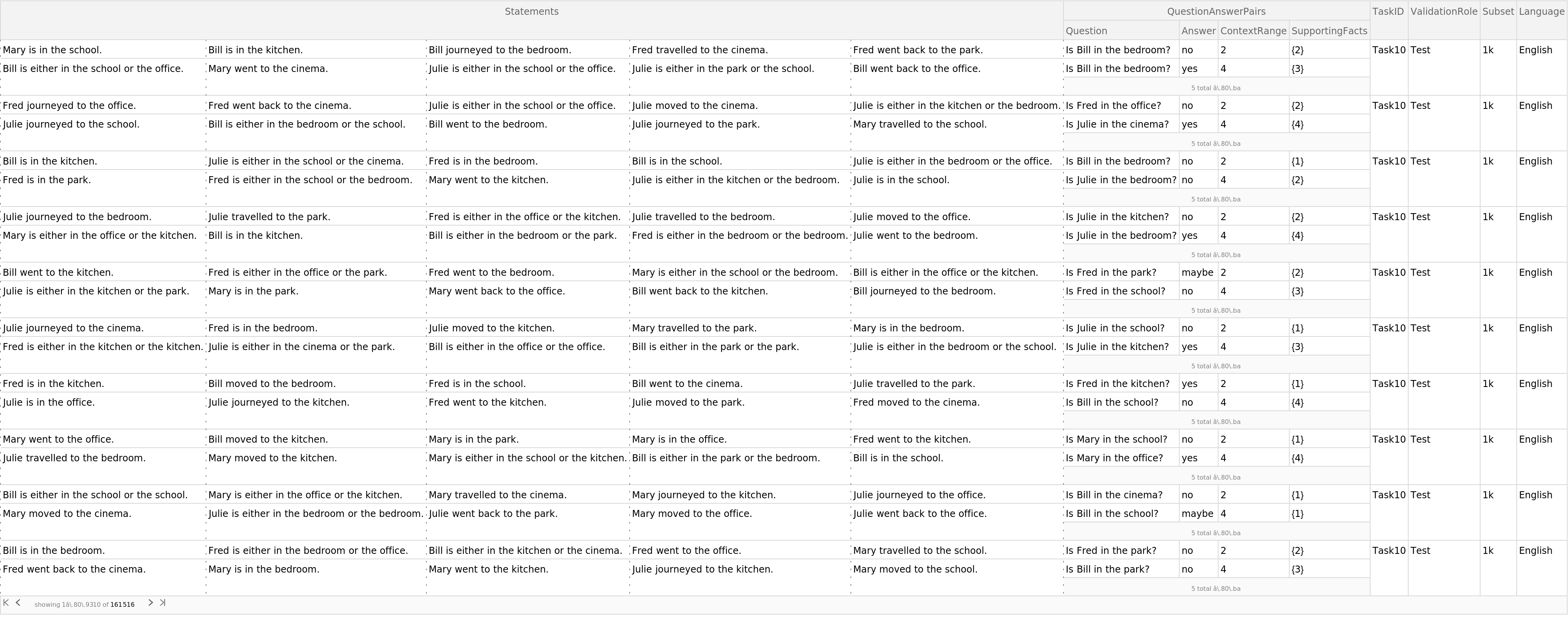 |
Select the Hindi-language subset:
| In[3]:= | ![ResourceData["The 20-Task bAbI Question-Answering Dataset v1.2"][
Select[#Language == "Hindi" &]]](https://www.wolframcloud.com/obj/resourcesystem/images/011/011954ec-59d9-4082-9959-b80502ad40f6/74c97e8a681b8b97.png) |
| Out[3]= | 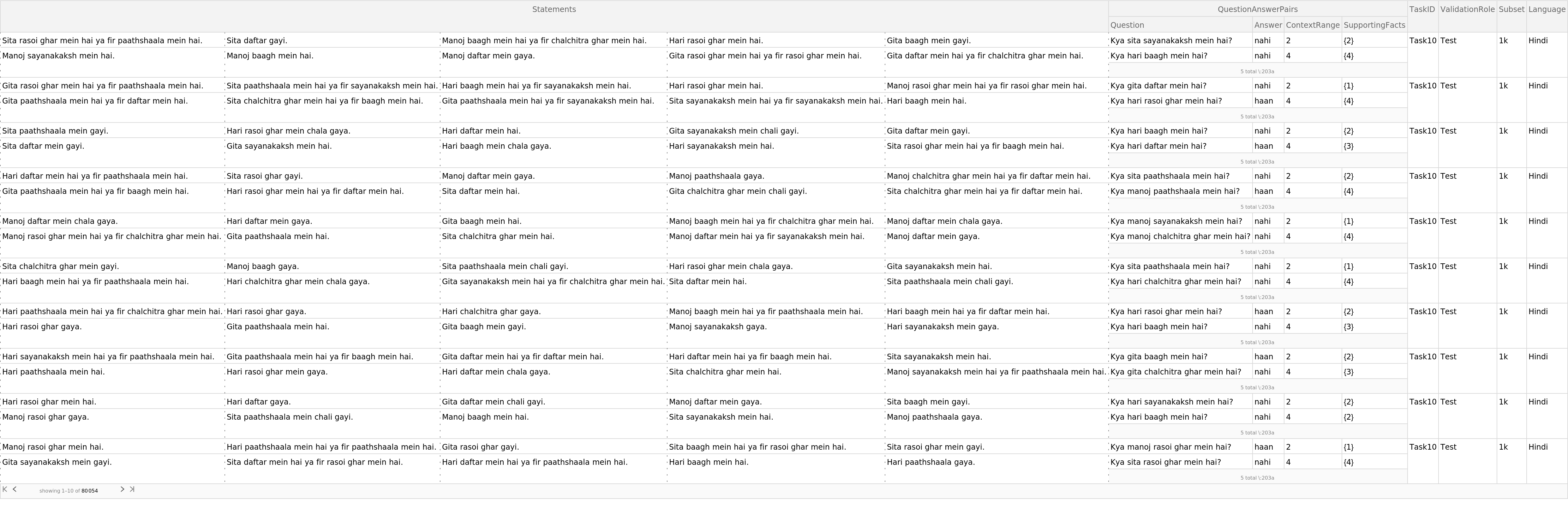 |
Obtain the training data:
| In[4]:= |
| Out[4]= |  |
Select the fifth example from "Task1":
| In[5]:= | ![ResourceData["The 20-Task bAbI Question-Answering Dataset v1.2", "TrainingData"]["Task1"][[All, 5]]](https://www.wolframcloud.com/obj/resourcesystem/images/011/011954ec-59d9-4082-9959-b80502ad40f6/24e0fbc13fb4ffb9.png) |
| Out[5]= |  |
Wolfram Research, "The 20-Task bAbI Question-Answering Dataset v1.2" from the Wolfram Data Repository (2017) https://doi.org/10.24097/wolfram.19270.data
Creative Commons Attribution 3.0 Unported (CC BY 3.0)