Wolfram Data Repository
Immediate Computable Access to Curated Contributed Data
Locations of cancer incidence annotated with larynx/lung marks
| In[1]:= |
| Out[1]= |  |
Summary of the spatial point data:
| In[2]:= |
| Out[2]= | 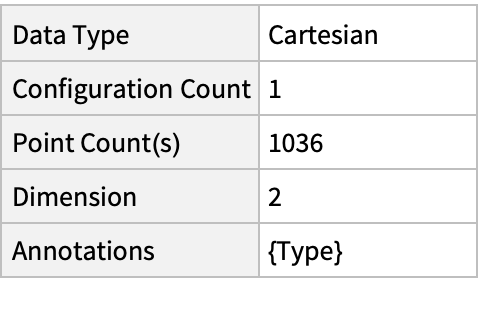 |
Plot the spatial point data:
| In[3]:= |
| Out[3]= | 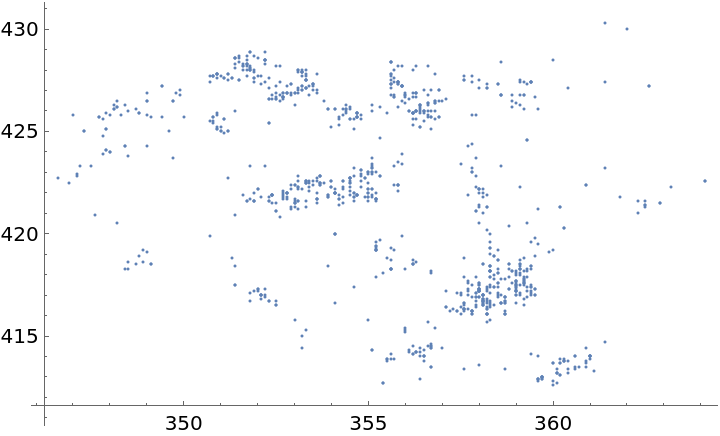 |
Visualize the data with the annotations:
| In[4]:= |
| Out[4]= | 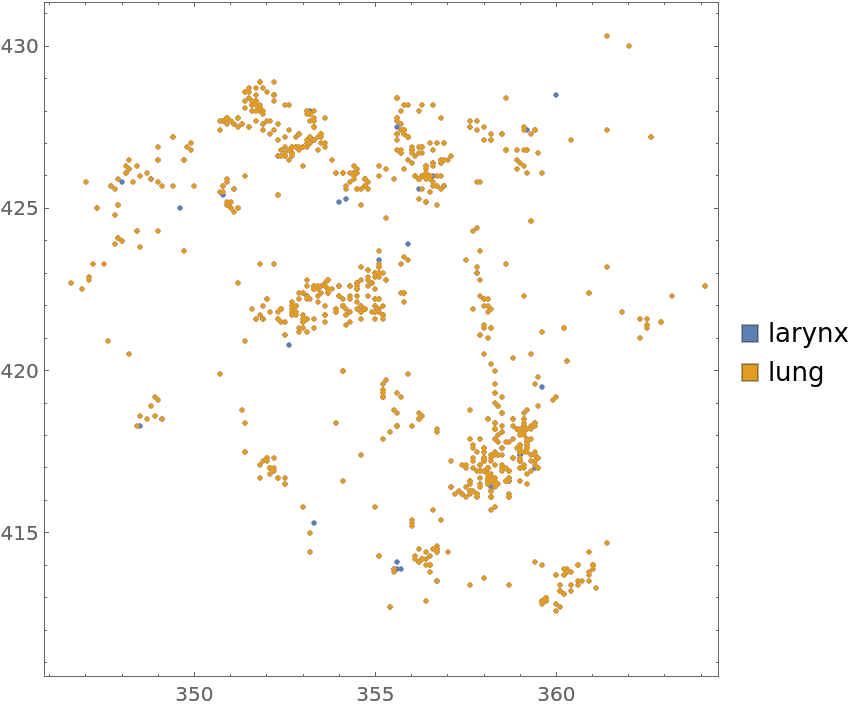 |
Visualize the smooth point density:
| In[5]:= |
| Out[5]= |  |
| In[6]:= |
| Out[6]= | 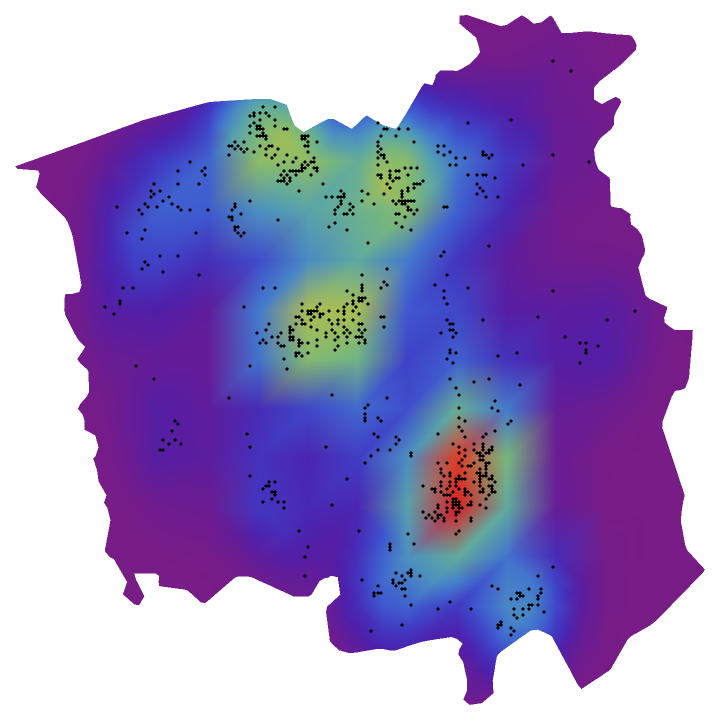 |
Compute probability of finding a point within given radius of an existing point - NearestNeighborG is the CDF of the nearest neighbor distribution:
| In[7]:= |
| Out[7]= |  |
| In[8]:= |
| Out[8]= |
| In[9]:= |
| Out[9]= | 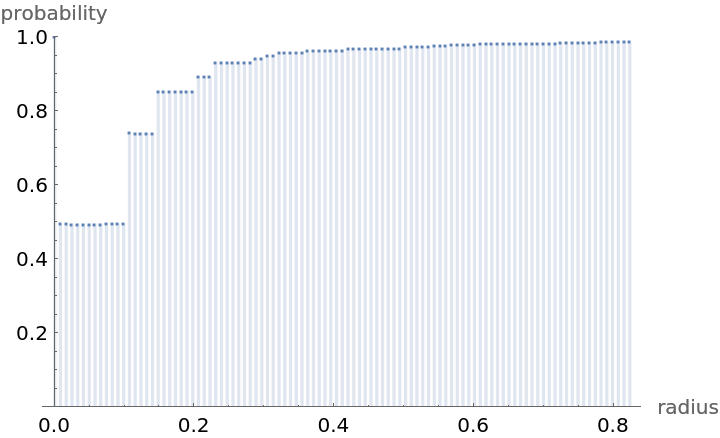 |
NearestNeighborG as the CDF of nearest neighbor distribution can be used to compute the mean distance between a typical point and its nearest neighbor - the mean of a positive support distribution can be approximated via a Riemann sum of 1-CDF. To use Riemann approximation create the partition of the support interval from 0 to maxR into 100 parts and compute the value of the NearestNeighborG at the middle of each subinterval:
| In[10]:= | ![step = maxR/100;
middles = Subdivide[step/2, maxR - step/2, 100];
values = nnG[middles];](https://www.wolframcloud.com/obj/resourcesystem/images/4b1/4b158472-c85c-49fe-bc1a-a1a76a6fefb8/79f87278711a4b7d.png) |
Now compute the Riemann sum to find the mean distance between a typical point and its nearest neighbor:
| In[11]:= |
| Out[11]= |
Account for scale and units:
| In[12]:= |
| Out[12]= |
Test for complete spatial randomness:
| In[13]:= |
| Out[13]= |  |
Gosia Konwerska, "Sample Data: Cancer Incidence" from the Wolfram Data Repository (2022)