Wolfram Data Repository
Immediate Computable Access to Curated Contributed Data
A parallel corpus for machine translation systems, information extraction and other language processing techniques
The Japanese-English Legal Parallel Corpus was created by crawling the Japanese Law Translation Database System. It contains parallel text of over 250,000 Japanese laws and over 4,000 legal terms.
The "ContentElements" field contains four options: "LawData", "DictionaryData", "LawDataset" and "DictionaryDataset". "LawData" and "DictionaryData" are structured as associations. "LawDataset" and "DictionaryDataset" are structured as datasets.
Obtain the first three examples of law text:
| In[1]:= |
| Out[1]= |
Obtain the first three examples of legal terms:
| In[2]:= |
| Out[2]= |
Obtain five random pairs from the set of laws in Dataset form:
| In[3]:= |
| Out[3]= |  |
Obtain five random pairs from the set of legal terms in Dataset form:
| In[4]:= |
| Out[4]= |  |
Obtain a character-level histogram of legal term lengths:
| In[5]:= | ![Histogram[
Map[StringLength, ResourceData["Japanese-English Legal Parallel Corpus", "DictionaryData"], {2}], ChartLegends -> Automatic, LegendAppearance -> "Column"]](https://www.wolframcloud.com/obj/resourcesystem/images/97a/97ab994b-dc3c-4138-94da-1b8d0e7d6dd9/62d449fe5a53c3e8.png) |
| Out[5]= | 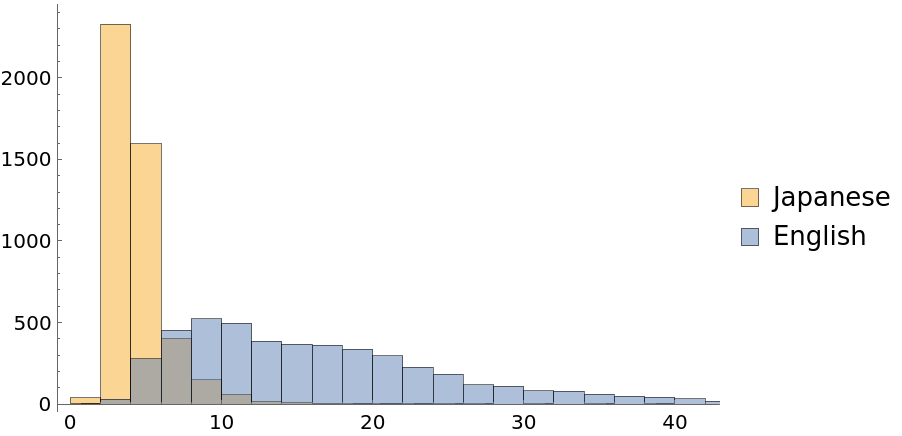 |
Wolfram Research, "Japanese-English Legal Parallel Corpus" from the Wolfram Data Repository (2018)
Japanese Law Translation Database System Standard Terms of Use