A parallel corpus for machine translation from the proceedings of the European Parliament
The Europarl dataset contains text corpora from 21 languages from the proceedings of the European Parliament between 1996 and 2011. The English-Spanish corpus contains 1.9 million training and 44,000 test sentences. Training examples are taken from the originally distributed parallel corpus, while test examples are extracted from the Q4/2000 portion of the data, following the publisher's suggestion. The "ContentElements" field contains four options: "TrainingData", "TestData", "TrainingDataset" and "TestDataset". "TrainingData" and "TestData" are structured as associations. "TrainingDataset" and "TestDataset" are structured as datasets. Duplicate examples have been removed from the test set.
Examples
Basic Examples
Retrieve the resource:
Obtain the first three training examples:
Obtain the first three test examples:
Dataset Form
Obtain ten random pairs from the training set in Dataset form:
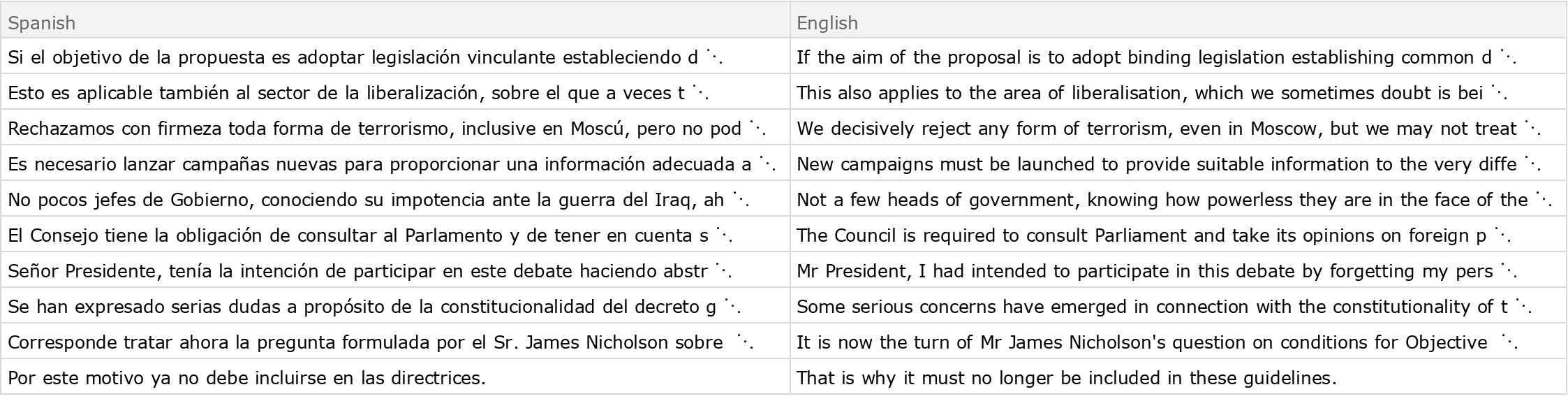
Obtain ten random pairs from the test set in Dataset form:
Analysis
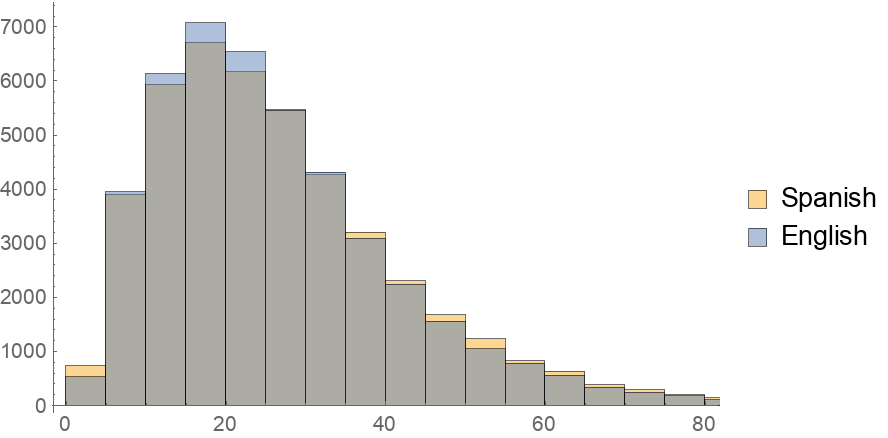
Obtain a character-level histogram of test example lengths:
Obtain a word-level histogram of test example lengths:
Bibliographic Citation
Wolfram Research,
"Europarl English-Spanish Machine Translation Dataset V7"
from the Wolfram Data Repository
(2018)
Reproduction is authorized, provided that the source is acknowledged
Data Resource History
Publisher Information




![Histogram[
Map[StringLength, ResourceData[
"Europarl English-Spanish Machine Translation Dataset V7", "TestData"], {2}], ChartLegends -> Automatic, LegendAppearance -> "Column"]](https://www.wolframcloud.com/obj/resourcesystem/images/75a/75ac51f5-1f98-4662-9401-fec484ced282/1f7f9fb90a99b8cf.png)
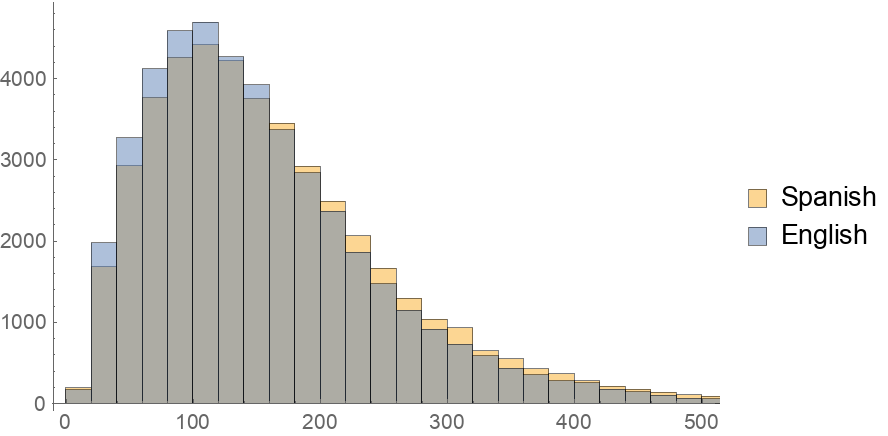
![Histogram[
ParallelMap[WordCount, ResourceData[
"Europarl English-Spanish Machine Translation Dataset V7", "TestData"], {2}], ChartLegends -> Automatic, LegendAppearance -> "Column"]](https://www.wolframcloud.com/obj/resourcesystem/images/75a/75ac51f5-1f98-4662-9401-fec484ced282/77ab708eb22368ee.png)