Wolfram Data Repository
Immediate Computable Access to Curated Contributed Data
A parallel corpus for machine translation systems, information extraction and other language processing techniques
The Japanese-English Subtitle Corpus (JESC) is the product of a collaboration among Stanford University, Google Brain and Rakuten Institute of Technology. It was created by crawling the internet for movie and TV subtitles and aligning their captions. It is one of the largest freely available English-Japanese corpora (3.2M parallel sentences), and covers the poorly represented domain of colloquial language.
The "ContentElements" field contains six options: "TrainingData", "TestData", "ValidationData", "TrainingDataset", "TestDataset" and "ValidationDataset". "TrainingData", "TestData" and "ValidationData" are structured as associations. "TrainingDataset", "TestDataset" and "ValidationDataset" are structured as datasets.
Retrieve the resource:
| In[1]:= |
| Out[1]= |  |
Obtain the first three training examples:
| In[2]:= |
| Out[2]= |  |
Obtain the last three test examples:
| In[3]:= |
| Out[3]= |  |
Obtain the one random validation example:
| In[4]:= | ![ResourceData["Japanese-English Subtitle Corpus", "ValidationData"][[All, RandomInteger[{1, Length@ResourceData["Japanese-English Subtitle Corpus", "ValidationData"]}]]]](https://www.wolframcloud.com/obj/resourcesystem/images/5cf/5cfc7b17-1658-4555-be52-50c04d2b6f94/6177923a21e642a3.png) |
| Out[4]= |
Obtain five random pairs from the training set in Dataset form:
| In[5]:= |
| Out[6]= | 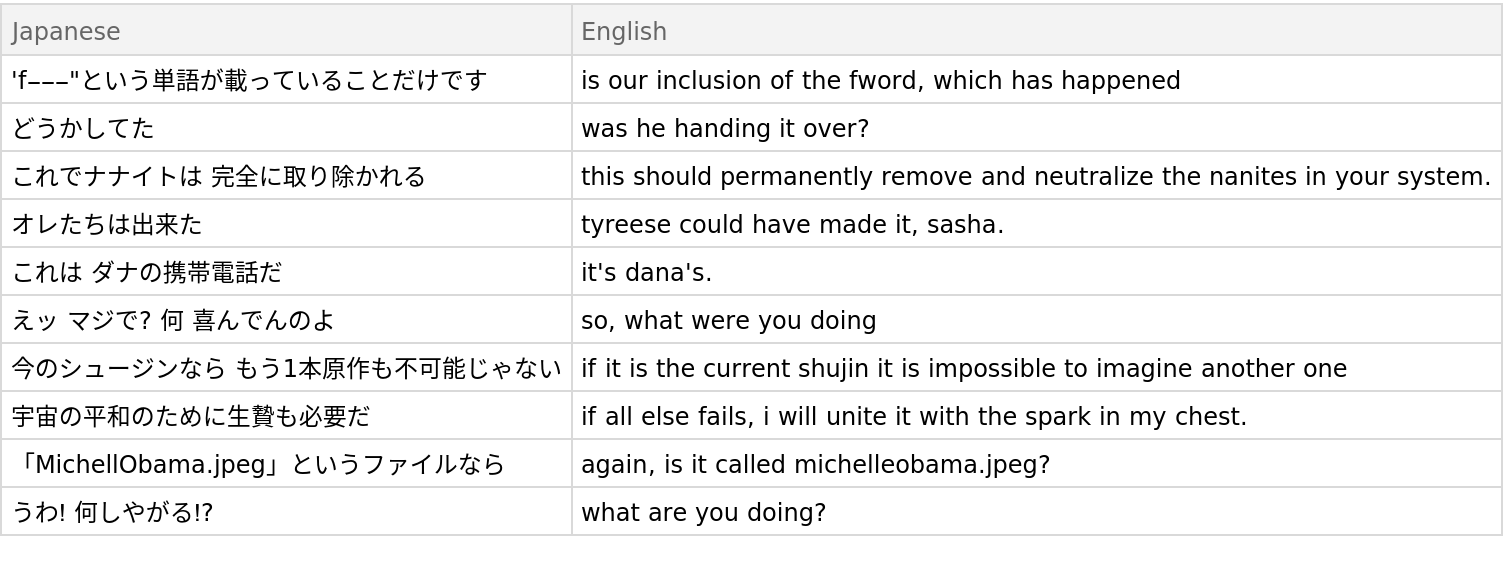 |
Obtain five random pairs from the test set in Dataset form:
| In[7]:= |
| Out[8]= | 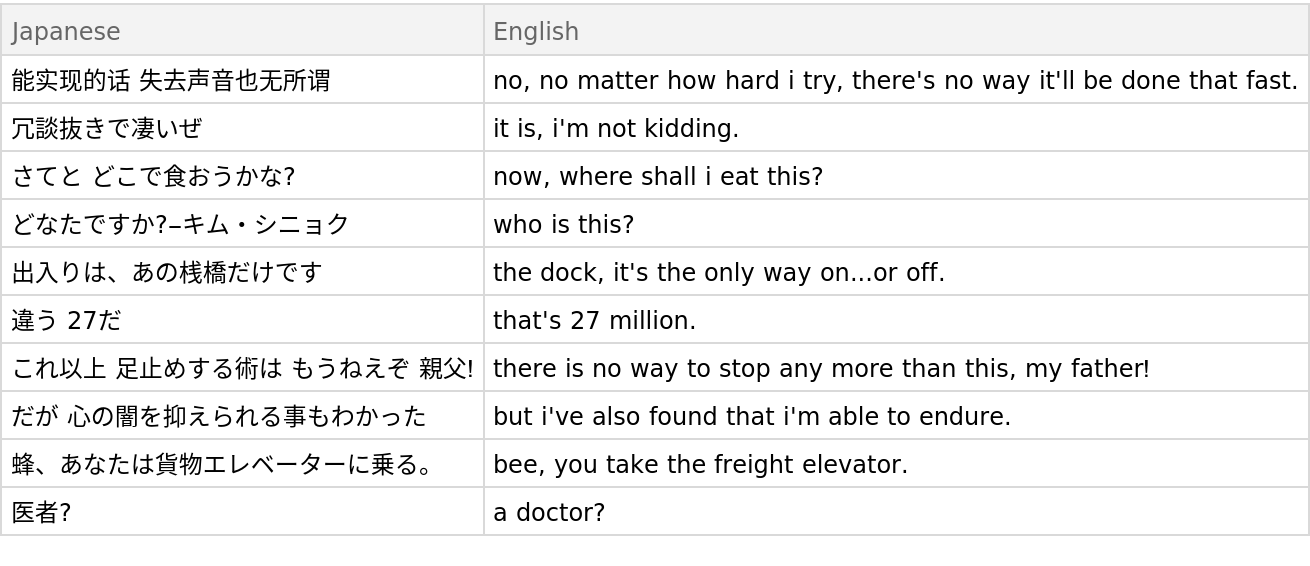 |
Obtain five random pairs from the validation set in Dataset form:
| In[9]:= |
| Out[10]= | 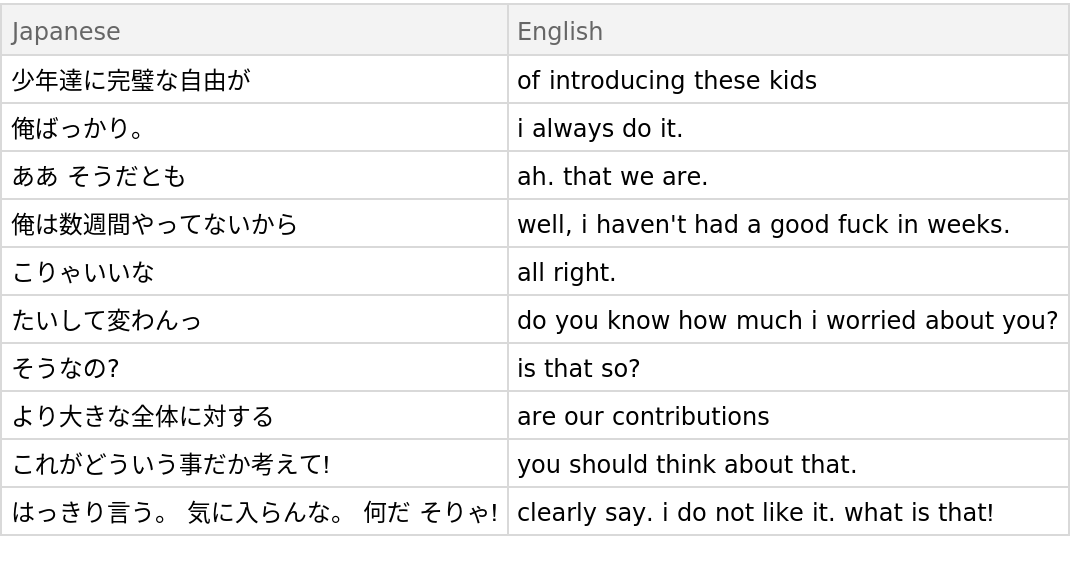 |
Obtain a character-level histogram of test example lengths:
| In[11]:= |
| Out[11]= | 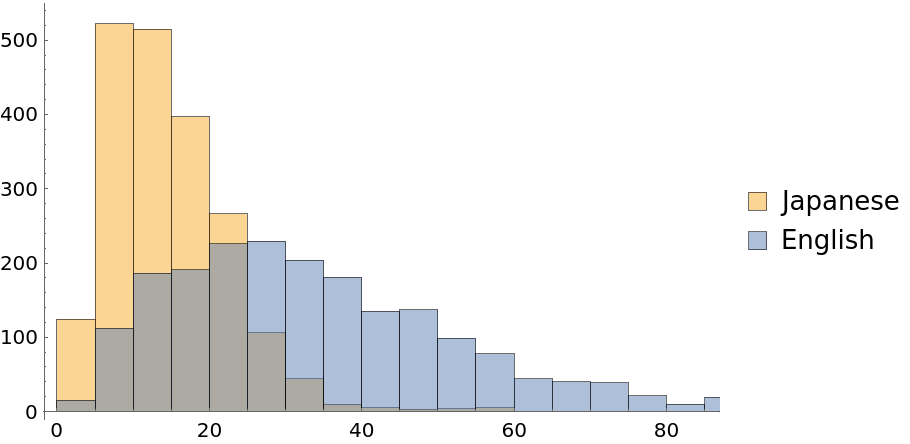 |
Wolfram Research, "Japanese-English Subtitle Corpus" from the Wolfram Data Repository (2018)
Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)