Wolfram Data Repository
Immediate Computable Access to Curated Contributed Data
A parallel corpus for the evaluation and development of Japanese-English machine translation systems
The data was originally prepared by the National Institute for Information and Communications Technology (NICT) and released as the Japanese-English Bilingual Corpus of Wikipedia's Kyoto Articles. The data was processed to form the Kyoto Free Translation Task dataset. Data was cleaned to remove sentences with fewer than 1 or more than 40 words, and separated into training, tuning, development and test sets. The training data should be used for training statistical models, tuning data used for tuning weights, development data used for testing the system in development and testing data used for reporting final results. The validation sets presented here correspond to the development set.
The "ContentElements" field contains eight options: "TrainingData", "TestData", "ValidationData", "TuningData", "TrainingDataset", "TestDataset", "ValidationDataset" and "TuningDataset". "TrainingData", "TestData", "ValidationData" and "TuningData" are structured as associations. "TrainingDataset", "TestDataset", "ValidationDataset" and "TuningDataset" are structured as datasets.
Retrieve the resource:
| In[1]:= |
| Out[1]= |  |
Obtain the first three training examples:
| In[2]:= |
| Out[2]= |  |
Obtain the last three test examples:
| In[3]:= |
| Out[3]= |
Obtain the one random validation example:
| In[4]:= | ![ResourceData["Kyoto Free Translation Task Data", "ValidationData"][[All, RandomInteger[{1, Length@ResourceData["Kyoto Free Translation Task Data", "ValidationData"]}]]]](https://www.wolframcloud.com/obj/resourcesystem/images/9c1/9c15cebb-5a65-48df-b074-35e150da8177/589ebcfe367c71a7.png) |
| Out[4]= |  |
Obtain the one random tuning example:
| In[5]:= | ![ResourceData["Kyoto Free Translation Task Data", "TuningData"][[All, RandomInteger[{1, Length@ResourceData["Kyoto Free Translation Task Data", "TuningData"]}]]]](https://www.wolframcloud.com/obj/resourcesystem/images/9c1/9c15cebb-5a65-48df-b074-35e150da8177/13ed96366cb48289.png) |
| Out[5]= |  |
Obtain five random pairs from the training set in Dataset form:
| In[6]:= |
| Out[6]= |  |
Obtain five random pairs from the test set in Dataset form:
| In[7]:= |
| Out[7]= |  |
Obtain five random pairs from the validation set in Dataset form:
| In[8]:= |
| Out[8]= |  |
Obtain five random pairs from the tuning set in Dataset form:
| In[9]:= |
| Out[9]= |  |
Obtain a character-level histogram of test example lengths:
| In[10]:= |
| Out[10]= | 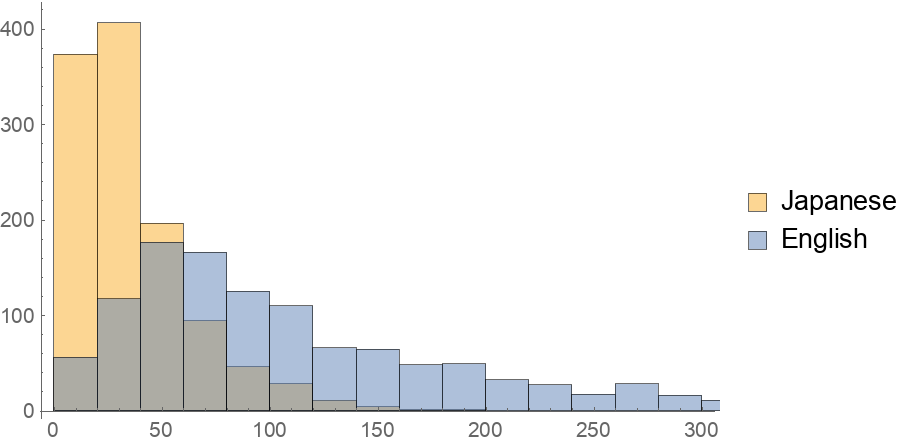 |
Wolfram Research, "Kyoto Free Translation Task Data" from the Wolfram Data Repository (2018)
Creative Commons Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0)