A dataset for question answering and reading comprehension from a set of Wikipedia articles
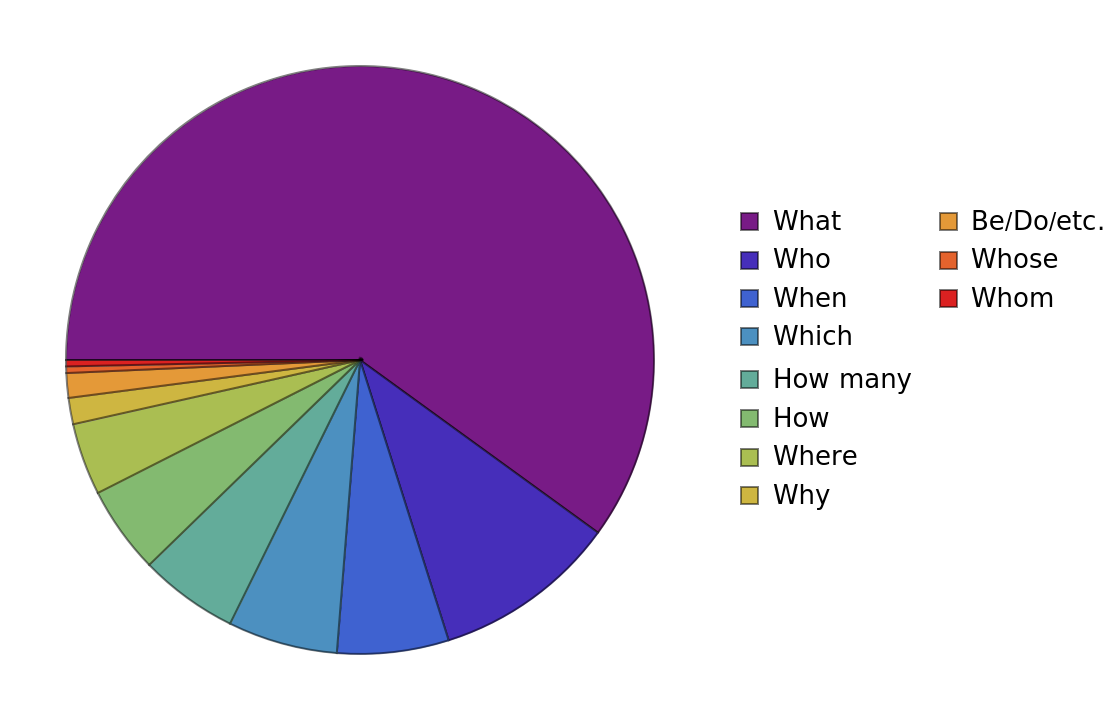
The Stanford Question Answering Dataset (SQuAD) consists of questions posed by crowd workers on a set of Wikipedia articles where the answer to every question is a segment of text, or span, from the corresponding reading passage. Unanswerable questions were added to the dataset for v2.0.
The "ContentElements" field contains eight options: "Dataset", "TrainingData", "ValidationData", "TrainingMetadata", "ValidationMetadata", "Data", "ColumnNames" and "ColumnDescriptions". "Dataset" contains the full dataset. Please note that data marked "Validation" in the ValidationRole field can have multiple possible answers for each question. "TrainingData" and "ValidationData" are formatted for standard question answering usage; for every question, only the first answer of the full dataset is selected. "TrainingMetadata" and "ValidationMetadata" contain the title of the Wikipedia article to which each question ID corresponds. "Data" contains the full dataset structured as an association. "ColumnNames" and "ColumnDescriptions" provide more information about the columns of the dataset.
Modifications from the original dataset: Data marked "Training" in the ValidationRole field corresponds to the Training Set v2.0 subset of the original dataset. Data marked "Validation" in the ValidationRole field corresponds to the Dev Set v2.0 subset of the original dataset. The original dataset is 0-indexed; in order be accurate in the Wolfram Language, 1 was added to the value of "AnswerPosition", as the Wolfram Language is 1-indexed.

![trainingSet = Join[ResourceData["SQuAD v2.0", "TrainingData"], ResourceData["SQuAD v2.0", "TrainingMetadata"]];](https://www.wolframcloud.com/obj/resourcesystem/images/713/71385e51-13f2-4ee0-8f1f-efa995a86575/307471b3480d5e45.png)

![patternToQuestionType = Append[StartOfString | (___ ~~ " ") ~~ ToLowerCase[#] ~~ ((" " | "," | "s " | "'" | "\"" | ":") ~~ __) | (PunctuationCharacter ~~ ("" | " " ...)) ~~ EndOfString -> # & /@ Most[questionTypes], StartOfString ~~ __ ~~ EndOfString -> Last[questionTypes]];](https://www.wolframcloud.com/obj/resourcesystem/images/713/71385e51-13f2-4ee0-8f1f-efa995a86575/4aef017d465c42ed.png)
![classifiedQuestions = Map[# -> StringReplace[ToLowerCase[#], patternToQuestionType] &[#] &, Flatten[Normal[ResourceData[\!\(\*
TagBox["\"\<SQuAD v2.0\>\"",
#& ,
BoxID -> "ResourceTag-SQuAD v2.0-Input",
AutoDelete->True]\)][[All, "QuestionAnswerSets"]][[All, All, "Question"]]]]];](https://www.wolframcloud.com/obj/resourcesystem/images/713/71385e51-13f2-4ee0-8f1f-efa995a86575/1e912f62f838f26a.png)