Wolfram Data Repository
Immediate Computable Access to Curated Contributed Data
Movie review data
This dataset consists of 10,662 snippets of movie reviews obtained from the review aggregator Rotten Tomatoes. Each review was labeled either positive or negative based on whether Rotten Tomatoes gave the movie a Fresh or Rotten rating, respectively. The test and training sets were constructed by stratified random sampling using 30% of the data for the test set and the rest for the training set.
Retrieve the resource:
| In[1]:= |
| Out[1]= |  |
Retrieve a sample of the dataset:
| In[2]:= |
| Out[2]= | 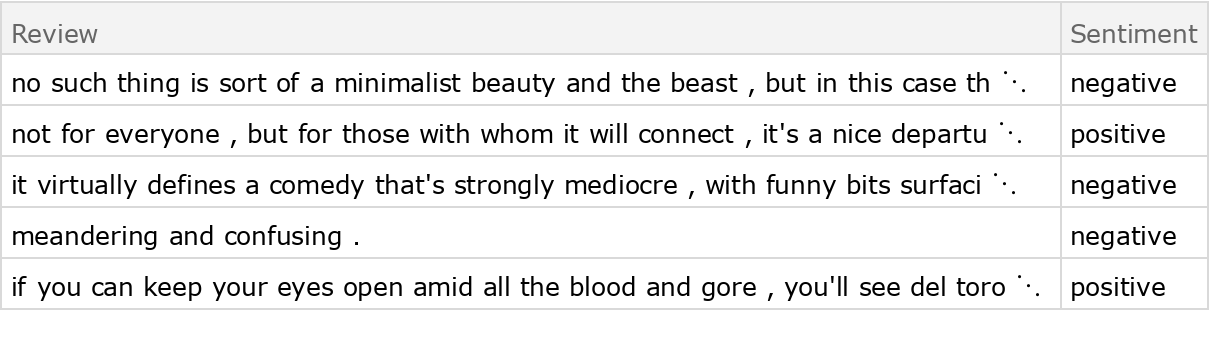 |
Train a classifier:
| In[3]:= |
| Out[3]= |
Obtain general information about the classifier:
| In[4]:= |
| Out[4]= | 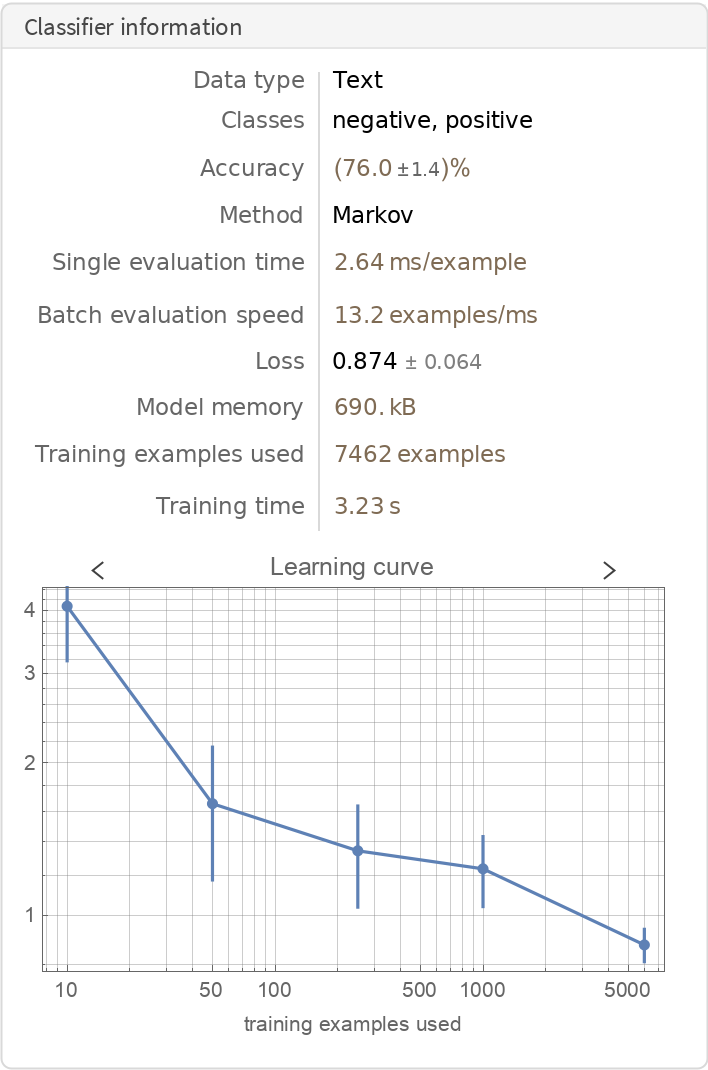 |
Visualize the accuracy of the classifier on the test dataset:
| In[5]:= | ![ClassifierMeasurements[classifier, ResourceData["Sample Data: Movie Review Sentence Polarity", "TestData"], "ConfusionMatrixPlot"]](https://www.wolframcloud.com/obj/resourcesystem/images/421/42149f40-1a59-4959-bb94-931915e994de/38db91ce83ca4adb.png) |
| Out[5]= | 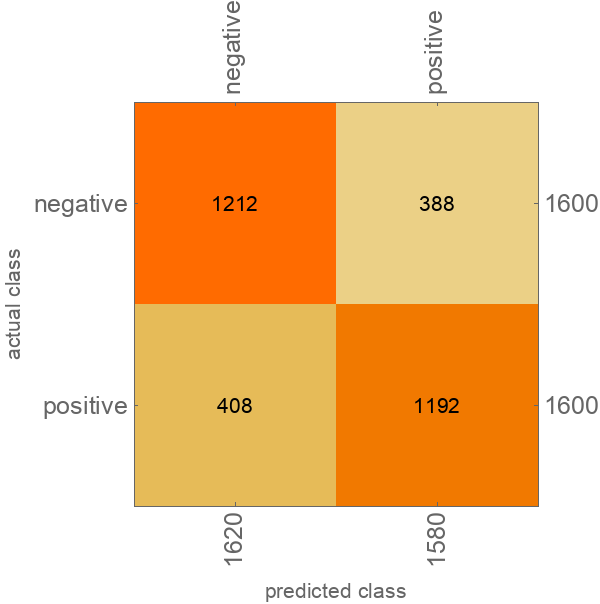 |
Wolfram Research, "Sample Data: Movie Review Sentence Polarity" from the Wolfram Data Repository (2019)