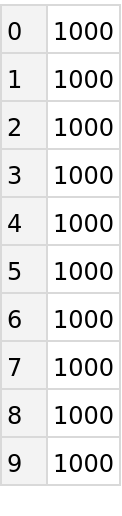
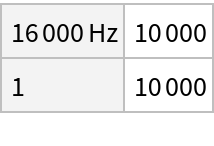
The dataset contains 10,000 training and 1,000 test recordings of 10 classes corresponding to spoken digits from 0 to 9. The total number of speakers is 997. The dataset is a subset of the Speech Commands Dataset v0.01 released by Google. The selection has been done so that speakers in the training and test sets do not overlap.
Examples
Basic Examples
Retrieve a sample of the training dataset:
Retrieve a sample of the test dataset:
Statistics
Compute the number of examples per class:
Compute the total number of different speakers in the training set:
Inspect the sample rate and channel count of the Audio objects:
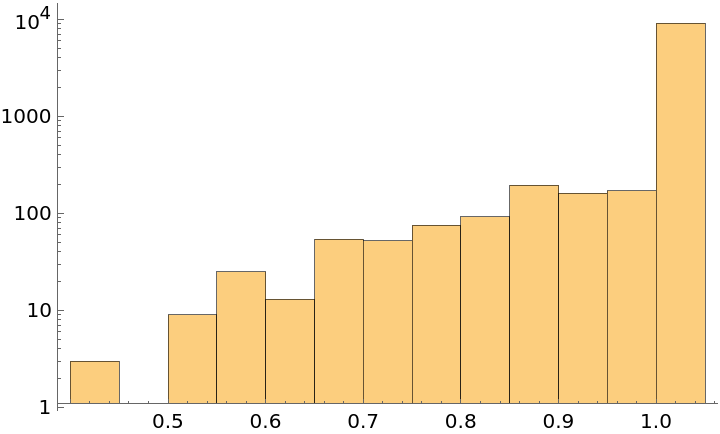
Plot the histogram of the durations of the Audio objects:
Visualization
Select an Audio object from the dataset:
Visualize the waveform:
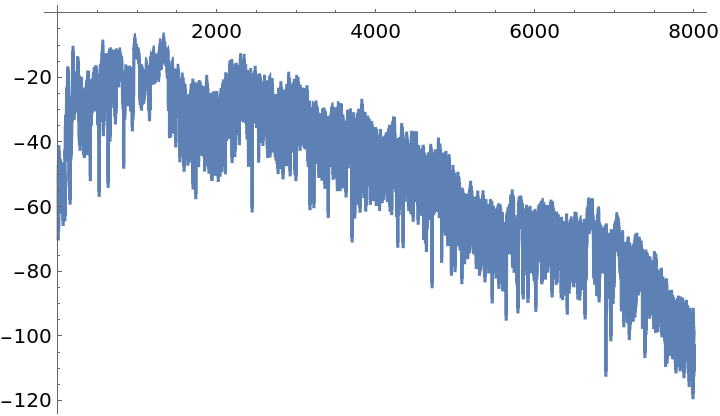
Visualize the spectrum:
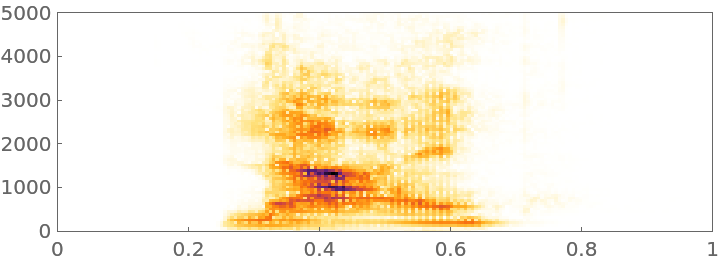
Visualize the spectrogram:
Bibliographic Citation
Wolfram Research,
"Spoken Digit Commands"
from the Wolfram Data Repository
(2018)
Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0)
Data Resource History
See Also
Publisher Information