Wolfram Data Repository
Immediate Computable Access to Curated Contributed Data
Locations of redwood saplings (young slender trees), annotated with binary indicator
| In[1]:= |
| Out[1]= |  |
Retrieve the default content:
| In[2]:= |
| Out[2]= | 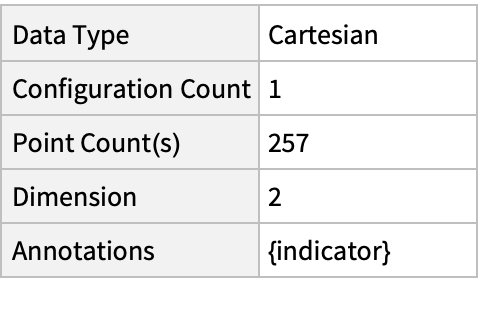 |
Plot the spatial point data:
| In[3]:= |
| Out[3]= | 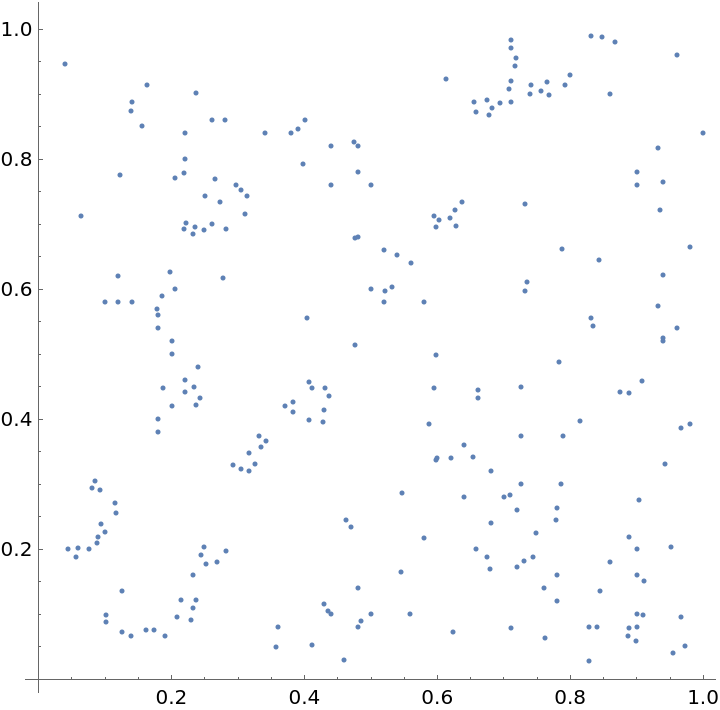 |
Visualize the data points with annotations:
| In[4]:= |
| Out[4]= | 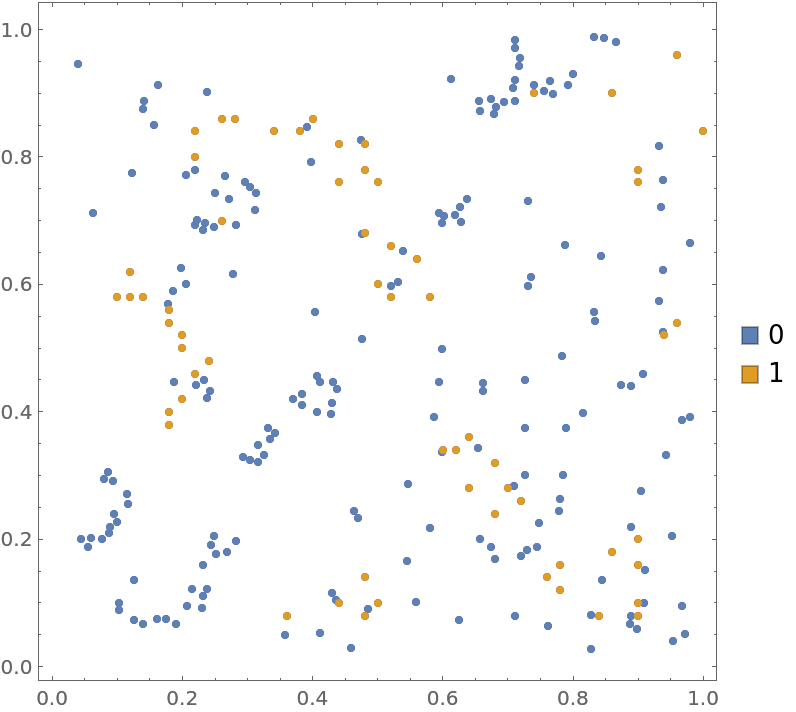 |
Visualize the smooth point density of the data:
| In[5]:= |
| Out[5]= |  |
| In[6]:= | ![Show[ContourPlot[density[{x, y}], {x, y} \[Element] ResourceData[\!\(\*
TagBox["\"\<Sample Data: Redwood Saplings\>\"",
#& ,
BoxID -> "ResourceTag-Sample Data: Redwood Saplings-Input",
AutoDelete->True]\), "ObservationRegion"], ColorFunction -> "Rainbow"], ListPlot[ResourceData[\!\(\*
TagBox["\"\<Sample Data: Redwood Saplings\>\"",
#& ,
BoxID -> "ResourceTag-Sample Data: Redwood Saplings-Input",
AutoDelete->True]\), "Data"], PlotStyle -> Black]]](https://www.wolframcloud.com/obj/resourcesystem/images/f7a/f7a7e31a-5cb7-41b5-b8e5-cfaf8ebe2076/6891a440d0d97690.png) |
| Out[6]= |  |
Compute probability of finding a point within given radius of an existing point - NearestNeighborG is the CDF of the nearest neighbor distribution:
| In[7]:= |
| Out[7]= |  |
| In[8]:= |
| Out[8]= |
| In[9]:= |
| Out[9]= | 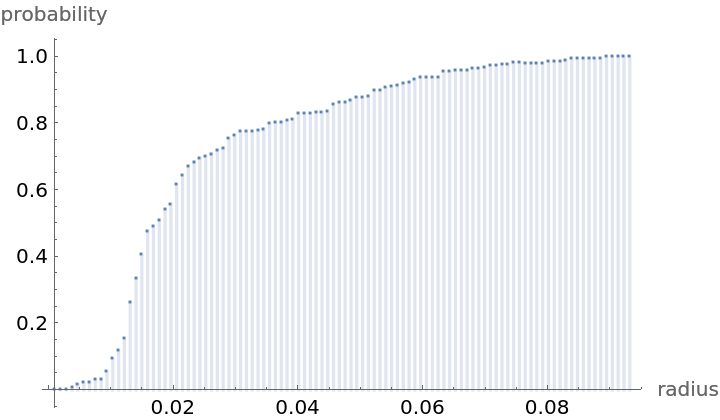 |
NearestNeighborG as the CDF of nearest neighbor distribution can be used to compute the mean distance between a typical point and its nearest neighbor - the mean of a positive support distribution can be approximated via a Riemann sum of 1- CDF. To use Riemann approximation create the partition of the support interval from 0 to maxR into 100 parts and compute the value of the NearestNeighborG at the middle of each subinterval:
| In[10]:= | ![step = maxR/100;
middles = Subdivide[step/2, maxR - step/2, 99];
values = nnG[middles];](https://www.wolframcloud.com/obj/resourcesystem/images/f7a/f7a7e31a-5cb7-41b5-b8e5-cfaf8ebe2076/03530e7e7532d3cf.png) |
Now compute the Riemann sum to find the mean distance between a typical point and its nearest neighbor:
| In[11]:= |
| Out[11]= |
Test for complete spatial randomness:
| In[12]:= |
| Out[12]= |  |
Gosia Konwerska, "Sample Data: Redwood Saplings" from the Wolfram Data Repository (2022)